Git better
You know what drives me crazy? When I need to figure out why some code is the way it is or why it changed in some way and the git history looks like this:
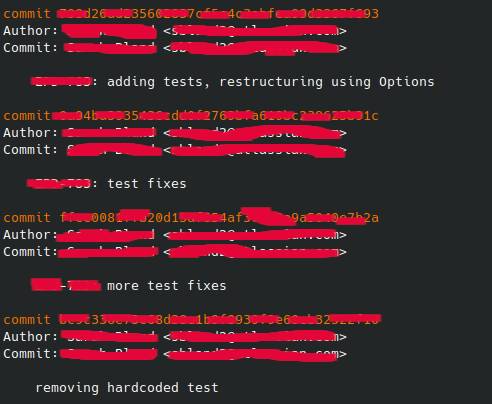
ℹ️ Got this with
git log --reverse --pretty=full --no-merges.ℹ️ The names and hashes have been scrambled to prevent blame and bad feelings.
This person was working on a PR and had some test failures and review comments and this is the resulting history that ended up in the main branch. I’ve talked with some engineers that think this is OK because you can see what they did which at the end of the day is what we want right?
Sure, we want a clear story of how the code changed and why but this isn’t that in my opinion. There’s no description of why something was being done (remember that this is the history with the full commit body), some of the commits are just fix-ups of previous commits, and without looking at the relevant PR to find comments or the Jira ticket to find the background.
In this particular case the Jira project where this work was originally tracked doesn’t exist anymore so I can’t read that anymore. The repo still exists and I can go find the PR but now I have to read through an old PR which also was missing any clear descriptions of what was going on and why (there was literally no description, just the title of the first commit). All that I can do is make educated guesses as to what was going on and what the team was doing at the time which sucks. Especially for really long lived teams which have had a lot of change. This is only slightly better than if there was no commit history at all.
We can do so much better.
⚠️ A quick note on using a GUI to do git commits
Personally I do all my git operations in the terminal but I don’t care if people want to use a GUI based tool instead just make sure that whatever you’re using looks better than this where you are stuck with an itty bitty, single line text box.
Anatomy of a commit message⌗
Let’s take a look at the basic anatomy of a git commit message.
High level summary of what changed (required)
Detailed description of what changed that can
be spread across multiple lines. (optional)
There are two main parts to a the message: the summary and the body.
⚠️ For both parts there are “requirements” on how long each line can be at max but there’s nothing that actually prevents you from going over those limits. You are just breaking a lot of conventions and are probably going to be working against the tooling.
Summary⌗
Of the two parts, this is the only one that is required and often gets done the least well. Here you should be providing a high level summary of what the change is. It’s limited to a single line and should not be more than 72 characters long.
ℹ️ Some people argue that the summary should be in past tense, some in the present tense. I don’t think it matters a ton so long as the developers on the project are consistent and the convention is documented.
The summary is super important and gets used in a lot of places to
represent the entire commit. For example, if you do a git log or
look at the list of commits on a PR you’re probably just going to see
a list of summaries. If you leave your summary super vague then it’s
not going to help whomever the reader is (that could be you) to
understand what each commit is for or how to read them.
Think of this part of the commit like a Tweet or an executive summary for someone who isn’t technical. You have to convey just enough information that it can be used to roughly understand the point of the commit without going into the weeds and going over your character/attention span limit.
ℹ️ Another restriction on this part of the commit message is that it MUST always be the first line of the commit message. There can’t be any lines in front it.
ℹ️ Some developers recommend keeping this less than 50 characters but that may not always be feasible or makes the commit worse.
Body⌗
The body of the commit is optional and is where you provide all the more nitty gritty details of what changed and why. It’s allowed to be multiple lines long. It follows the summary (with a blank line in between the two) and each line should be less than 72 characters in length.
The body of the commit is your chance to really go in depth on what what happened. You can provide code snippets, justification for what happened, explain the pros/cons and your reasoning for doing something. I suppose it’s possible to go into too much detail here but I’ve never actually seen that happen.
Because this section is optional people almost always leave it off which is a shame because you’re now stuck with 72 characters to explain the entirety of what you did which you’re only going to be able to do for the simplest of changes. There are certainly times where it makes sense to leave off but those times should be few and far between in my opinion.
Making commits useful⌗
Now that we know what a commit message should roughly look like let’s see how we can make them useful.
The following are all recommendations on what you can do to improve your commit messages. You can use some, none, or all of these ideas just try and be consistent in each repo. It would also be a good idea to come up with conventions for your team so that you can all be talking the same language so to speak.
Explain the point of your change⌗
As I mentioned earlier, I don’t think that someone who is reading your commit message should have to go consult a few different places figure out why you made this change. The more places you have to look, the more likely you are to have one or more of those external links go dead or for the reader to give up.
Your job is to make it easy to read what happened and part of that is explaining the context around your change. You don’t need to regurgitate the entire Jira ticket but give a high level explanation. If that’s still not enough then the reader can go do some more research.
ℹ️ Try and explain the context that arose before you made your change.
ℹ️ Explain how your change works. The more complicated the change is (or the less obvious it is) the more detail you should give.
ℹ️ Is there some risk to what you’re doing that others should know about?
ℹ️ Does this change depend on other changes? Are there going to be more changes that are coming that should be factored in by readers?
ℹ️ Do you have any references that might be helpful for readers?
Including ticket numbers⌗
Most hosted git solutions (Github, Gitlab, Bitbucket, etc) all have support for linking to ticket numbers and you should absolutely take advantage of this.
My team for example will prefix just about all our commits summaries with the Jira ticket that the commit belongs to. Jira is then linked to our repos so you can go from the commit message to the Jira ticket or see all the commits from the Jira ticket. This makes it super easy for other people to see how work is related and can be used for someone else to pick up your work if you get sick or have to take a leave of absence unexpectedly.
Say you have a Jira project with TEST as the project slug. If you
were working the ticket TEST-1234 then you could have a commit
that looks something like this:
TEST-1234: Added new options page for mailing list unsubscribes
To comply with the new legal requirements we've added a new page that
will allow users to unsubscribe from our mailing list. The user must
provide the email address that they want to unsubscribe.
In this first iteration of the page we unsubscribe the user from every
type of email but in the future we'll add support for opting out of
specific email types (marketing vs newsletter vs account updates).
Depending on your tooling you may be able to reference the ticket in
other ways or there might be restrictions on where you can put the
link. Consult your doctor the documentation for more details.
Use markdown⌗
Most of the git tools that I’ve used have at least some support for CommonMark style markdown in commit messages which can be super helpful to add even more readability to your change.
ℹ️ Even if the tool doesn’t actually render the markdown as expected it’ll probably still be readable and be better than only using words.
You could include tables, lists, code snippets, and more to get your point across.
TEST-1234: Added fine-grained user opt-outs from mailing list
Following on from previous work, we're adding on the ability for users
to opt-out of specific types of emails from our mailing list. The
currently supported types of emails are:
* marketing
* newsletter
* account-updates
Users can opt out of 1 or more types at the same time. This is the
final planned change for this opt-out epic.
Give code samples⌗
Building on from the markdown suggestion, you can also include additional code snippets in your commit message. These will likely not be snippets from the actual change itself but instead some sample code that is related in some way to your change however you could still highlight a specific part of the code if that helped make things more understandable.
TEST-2345: Added rule for requiring descriptions on lint opt-outs
This new lint rule requires developers to include a description for
why some other lint rule was disabled for some chunk of code.
This is important because we should be explicitly calling out why we
are disabling a lint rule since the linter is there to catch bugs,
keep code consistent, and generally keep you from doing something
silly. By not including a description it's not clear to readers why
the linter is being disabled or when it might be enabled again.
An example of code that would not fail because of this rule would be:
```typescript
// eslint-disable-next-line @typescript-eslint/ban-ts-comment
// @ts-ignore
const value: string = [];
```end
Instead you would need to write something like this:
```typescript
// eslint-disable-next-line @typescript-eslint/ban-ts-comment -- we want to test invalid types from the API
// @ts-ignore
const value: string = [];
```end
Extra documentation on this rule can be found here:
https://mysticatea.github.io/eslint-plugin-eslint-comments/rules/require-description.html
Use conventional commit message formatting⌗
Another interesting approach to formatting your commit messages is to follow the Conventional commit format.
The nice thing about this format is that you can easily hook it into an auto versioning tool like Semantic release or my preferred alternative go-semantic-release.
The general idea is the summary of your message includes a category
for the change. If you were just fixing a test you might use the
test category. Or if you’re adding a new feature you would use
feat. This communicates how big the change might be to consumers as
well as allowing tooling to try and understand how this change might
affect others.
You can even use a pre-commit hook to enforce that others are following this format.
feat: Added a new CLI option for filtering out commits
The new `--filter` option can be given to specify a category of
conventional commit formatted git commits to include in the output.
Example usage: `--filter=test`
This would include only `test` category of commits.
Use commits to tell a story⌗
Your git commits should tell a story, it’s up to you what kind of story that is. I mentioned previously that you can and sometimes should reference other commits when making a new commit but you can do more.
Sometimes when you’re working on a big change you’ll end up with one super big commit that is going to just really suck to go through as a PR reviewer. Or maybe you’ll have a whole string of these unrelated, but small, commits like the ones in the original example I gave. What kind of story are these commits telling and how pleasant are they going to be to read?
This is where git rebase can come in.
Rebase is a very powerful command that can allow you to reorder, reword, squash, split, and drop commits. By rewriting your commit history you can make something that is easier to follow and reason about.
⚠️ This command can also be dangerous if used improperly or carelessly so when you use it be very careful.
⚠️ You should also only be rebasing your own commits since you wouldn’t want to overwrite someone else’s work.
Let’s look at some examples of how this could be used.
Rewording a commit after things change⌗
This first example is pretty straightforward. Say you made a commit in a bit of a rush. You could have been just trying to push your changes up to the remote so someone else could look at it. Or maybe you weren’t sure if something would work and wanted to run it in CI. It doesn’t matter the reasoning but you have some commits that don’t have great descriptions.
Here we’re entering interactive rebase mode using
git rebase --interactive <remote>/<branch>. We then see a list of
our commits which our in our branch and not in the remote branch. By
default each commit will get the pick operation however there are a
bunch of other operations listed in the comment below our list of
commits.
🔍
pickjust uses the commit as is without any changes.
Here we’re just going to use the reword operation to update the
message and then use the rest of the commit as is.
Splitting a big commit into multiple, smaller commits⌗
Some times you’ve made a change that resulted in a really big commit or maybe you’ve got a bunch of smaller changes that ended up in your one commit. You could split them up into smaller commits that could be consumed on their own. This can make it easier to review your change since the reviewer could just look at one commit in isolation and take a break or ignore all the other stuff in your PR. This is especially helpful when your PR is touching a ton of stuff and you want to keep your reviewers from getting overwhelmed.
Again we’re entering interactive rebase mode with
git rebase --interactive <remote>/<branch>. And as before we see our
list of commits. In this case though we want to split that middle
commit up into two commits which we can do with the edit operation.
🔍
editcauses rebase to stop at the selected commit and normally this is your chance to edit the commit message OR the content of the commit itself.
We’re then using git reset HEAD~ to unstage the changes in our
commit. We can then commit some of the changes with a separate commit
message and then stage up the next set of changes with their it’s own
message.
Merging fix-up commits together⌗
You can also find yourself making tons of little commits while working
on a task but each task doesn’t really stand on it’s own. Examples of
this are fixes for CI, realizing your branch deployment doesn’t work,
or fixing a typo. Having a commit that’s just fixed tests isn’t
helpful. You can take all these micro commits and join them together
into a single commit. You can even reorder them while merging them!
There are two ways to do this while rebasing. Using squash and
fixup.
🔍
squashtakes a set of commits and joins them together into a single commit while preserving the individual commit messages. This can be helpful more when merging a PR which multiple commits.🔍
fixupis very similar tosquashexcept only one commit message is preserved in the output. I almost always end up usingfixupoversquashin my workflow.
Again we’re entering interactive rebase mode with
git rebase --interactive <remote>/<branch>. And as before we see our
list of commits. Now though we are going to start by moving some of
the commits around by just moving the commits around in the list. This
will affect the output and can be a skill on its own. Finally we then
mark the commits that we want to squash into a previous commit. You
can mark as many consecutive commits as you want.
Dropping experimentation commits⌗
The final type of operation I want to talk about is the one for
dropping commits that you don’t want anymore. I usually end up using
this when I’m trying out a possible solution and realize that it’s not
the approach I’m going to stick with. I could just do a fixup
instead but that doesn’t feel right to me semantically.
🔍
dropliterally drops/removes the commit from the git history.
Again we’re entering interactive rebase mode with
git rebase --interactive <remote>/<branch>. And as before we see our
list of commits. This time we select which commits we want to remove
and tell git to drop ‘em. That’s it. It’s really easy, just make sure
you drop only the commits you actually want removed.
Wrap up⌗
This is kind of just the beginning of the many things you can do to improve your commit messages and I seriously urge you to up your game there. There’s likely wins that you can get without a ton of effort and the payoff is a much more readable git history and having to spend a lot less time looking at meaningless messages when you’re trying to figure out why something is the way it is.
Just find a commit message format that works for your team, document it, if possible enforce it with tooling, and review it periodically to make sure that it’s actually working for you.